
Uno dei passi fondamentali nella progettazione di un database è la determinazione della su struttura che consiste in:
1)Tipologia di dati memorizzati
2)Tabelle necessarie per la rappresentazione dei dati
3)Campi necessari per la rappresentazione dei dati
4)Determinare l’identificazione univoca dei record
5)Determinare le relazioni tra le tabelle
Per prima cosa quindi , nella progettazione di un database, è necessario identificare e stabilire che tipo di informazioni si desidera rappresentare. In base a questa identificazione è possibile determinare le tabelle necessarie e quindi tutta la struttura della base di dati. Una volta identificate le informazioni che si desidera memorizzare, si passa alla definizione delle tabelle, ossia delle entità che rappresentano i dati. Le informazioni devono essere quindi suddivise in gruppi omogenei, in modo tale da poter creare delle tabelle che contengano dati relativi ad una sola entità o argomento. Inoltre si deve tener conto della ridondanza (o ripetizione) dei dati: i dati memorizzati nelle tabelle non devono essere ripetuti o quanto meno questa ridondanza deve essere ridotta al minimo indispensabile.
Esempio
Nella definizione di un database scolastico si memorizzeranno, in tre tabelle distinte, i dati anagrafici degli studenti, gli esami da affrontare per il corso di studi e gli esami superati.In questo modo, quindi, si eviterà di riscrivere i dati anagrafici di ogni singolo studente, per ogni esame che questi sosterrà. Allo stesso tempo verranno tenuti separati i dati “anagrafici” del singolo esame (come ad esempio data, aula, tipologia, numero domande e percentuale di superamento) dai risultati ottenuti da ciascun studente.
Determinare i campi
Una volta identificate le tabelle, si possono determinare e definire i campi che le compongono. Ciascun campo di ogni tabella deve contenere i singoli dati che definiscono e compongono l’entità stessa.Una tabella inoltre non dovrebbe contenere informazioni duplicate; se una tipologia di informazioni deve essere ripetuta più volte, potrebbe essere forse necessario ridefinire le tabelle e magari suddividere le informazioni ripetute in un’entità a parte.La definizione dei campi prevede non solo l’identificazione delle singole informazioni, ma anche il tipo di dato utilizzato per la rappresentazione.
Identificare i record in maniera “univoca”
Una volta riempito, in un database sarà necessario effettuare operazioni di lettura sui dati in esso memorizzati. Operazione quindi indispensabile è quella di identificare un cosiddetto campo chiave, attraverso il quale sarà possibile in qualsiasi momento, posizionarsi e leggere nel modo più veloce possibile, il record di nostro interesse. Il campo chiave inoltre, è indispensabile come vedremo più avanti, per creare un legame di relazione tra una o più tabelle.La chiave di una tabella può essere composta da uno o più campi; è inoltre possibile, anche se fortemente sconsigliato, creare delle tabelle senza chiave. Una tabella senza campo chiave, infatti, non si può relazionare con altre, e perde di senso nella concezione dei database relazionali. Un campo o un insieme di campi che identificano in modo univoco un record è chiamato chiave primaria.
Stabilire le relazioni tra le tabelle
Dopo aver identificato le informazioni e quindi suddivise le stesse in tabelle, e dopo aver identificato la struttura delle tabelle in campi e campi chiave è necessario, in un database relazionale, definire come le varie tabelle sono correlate tra di loro, e quali campi fanno quindi da “legante”. Ipotiziamo di avere una tabella studente e una tabella Esami_sostenuti queste due potranno essere messe in relazioni tramite il campo chiave Matricola.
Le relazioni tra tabelle
Nei database relazionali, le relazioni tra tabelle sono indispensabili proprio perché ci permettono di organizzare i dati in maniera ordinata e strutturata, permettendoci quindi di reperire tutte le informazioni in modo veloce, seppur memorizzate in tabelle diverse.La relazione tra due o più tabelle avviene grazie alla definizione di un legame.Il legame è dato dalla presenza dello stesso campo in entrambe le tabelle. Solitamente questo campo è un campo di tipo chiave primaria in una delle tabelle relazionata e detto, quindi, di tipo chiave esterna nell’altra.
Tipologie di relazioni
Nei database relazionali esistono tre tipi di relazione :
• Uno ad uno – Ad ogni record contenuto in una tabella corrisponde un solo record di una seconda tabella.
• Uno a molti – Ad ogni record di una tabella corrispondono più record contenuti in una seconda tabella.
• Molti a molti – A più record di una tabella corrispondono più record contenuti in una seconda tabella.
Relazione “uno ad uno”
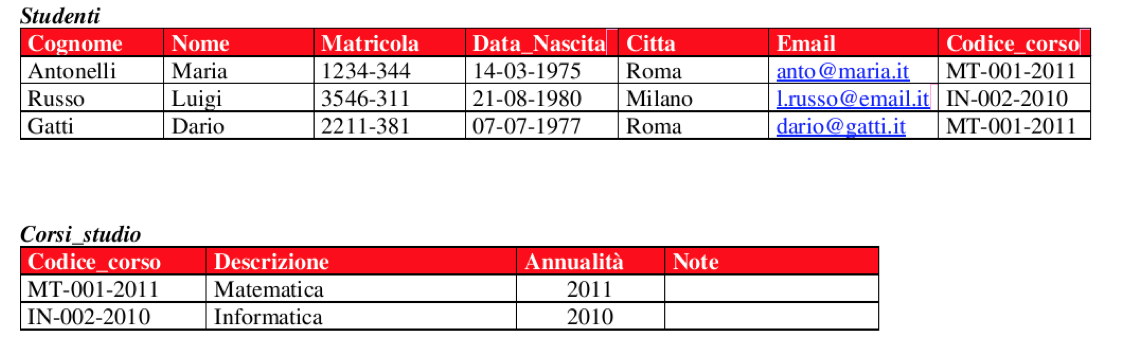
Come si può notare, il campo Codice_Corso relaziona tra loro le due tabelle ed evita di dover riscrivere le informazioni “anagrafiche” di un corso per ogni studente iscritto.
Relazione “uno a molti”
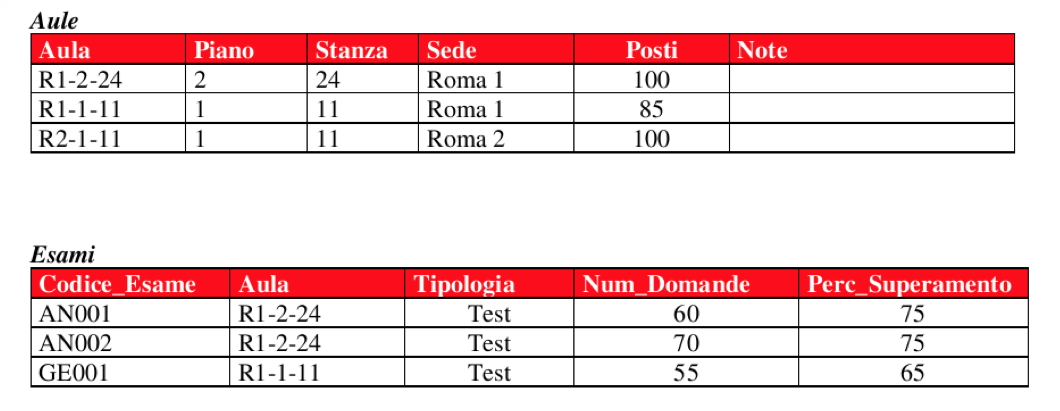
Come si può notare dall’esempio, ad un’aula possono corrispondere n^ esami. In questo caso si parla quindi di relazione “uno a molti”.
Relazione “molti a molti”
Probabilmente la più complicata da comprendere e realizzare, questa relazione stabilisce che a più record di una tabella corrispondono più record contenuti in una seconda tabella.
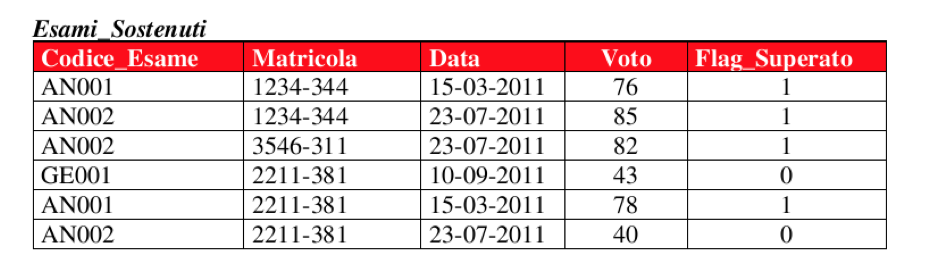
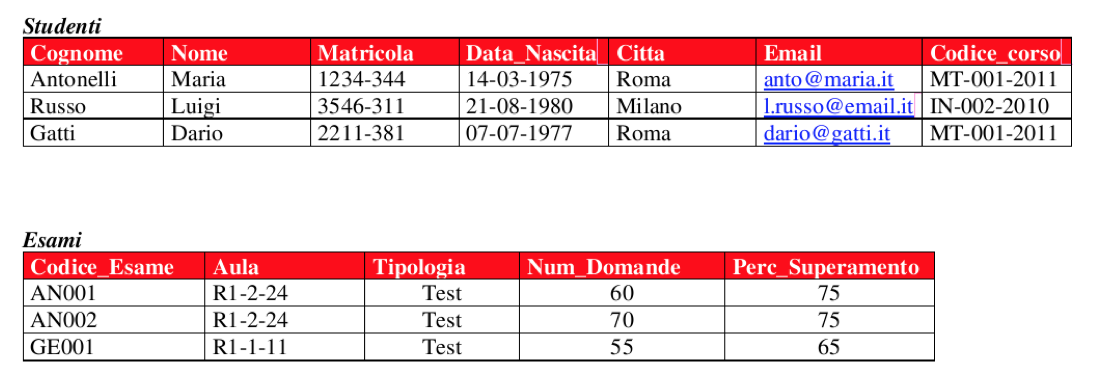
Come si può notare dall’esempio, a tanti esami corrispondono tante prove di tanti studenti. In questo caso si parla quindi di relazione “molti a molti”.